作者:股民连长 | 来源:互联网 | 2023-09-24 09:41
篇首语:本文由编程笔记#小编为大家整理,主要介绍了pytorch案例代码相关的知识,希望对你有一定的参考价值。
学习于刘二大人课程
最简单的线性回归
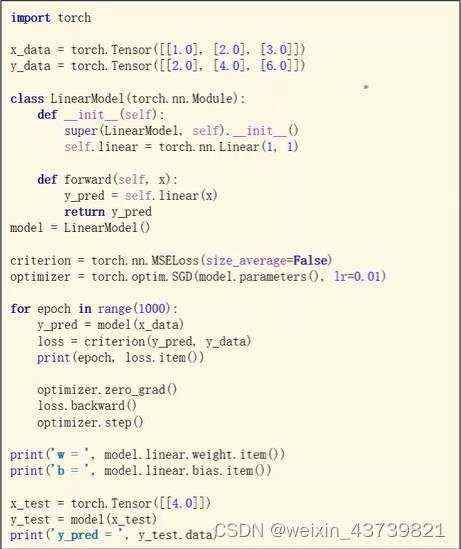
这里MSELoss是求均方误差的,其用来反应估计量与被估计量之间差异程度。
定义优化器中传入的第一个参数model.parameters()是为了告诉优化器哪些tensor需要去梯度下降来优化的,这个parameters会检查model里的所有成员,如果这些成员里有相应的权重,就都会把它们加入到训练的结果里,这里的model里只有一个linear的w和b。

最简单的逻辑斯蒂回归(softmax)(二分类)
improt torch.nn.functional as F
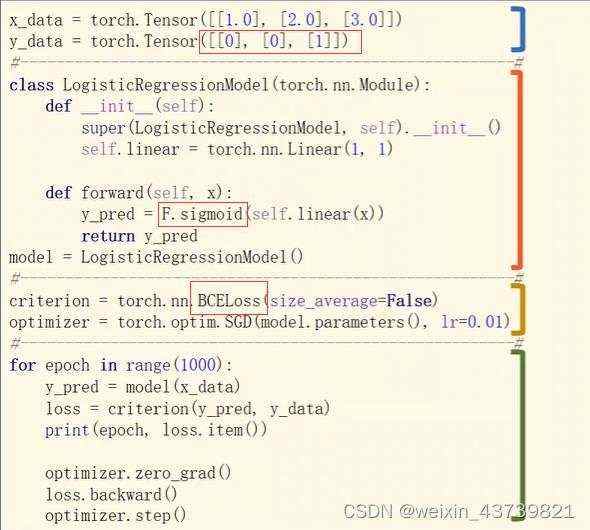
这里BCELoss是二值交叉熵损失的,适用于0/1二分类。
多维数据多层神经元网络逻辑斯蒂回归(二分类)
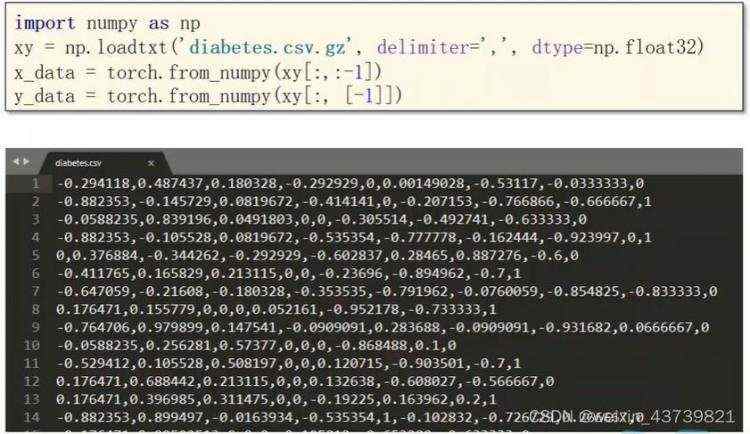
gz是linux中压缩文件格式,loadtxt可以读csv也可以读csv.gz。
这里读取数据类型写成np.float32不写成double是因为大部分GPU只支持32位浮点数。
读取y数据的列切片要写成[-1]而不是-1因为我们希望拿出来的是矩阵而不是向量,torch的运算支持广播,矩阵运算比标量运算要快得多。

初始化函数中sigmoid的定义不同于之前的torch.nn.functional.sigmoid,这里是继承自module的。
forward的定义里一直用x变量是默认写法。


加载数据集
在mini-batch中,batch-size就是字面意思,Iteration等于样本总数除以batch-size。
需要用到俩个库,第一个是Dataset,用来构造数据集,数据集支持索引访问(下标),其是一个抽象类,即不能实例化,需要我们定义一个继承它的类才能实例化一个对象使用。定义这个类的init()时,针对数据集的大小有俩种定义方法,因为数据太大时不可能一次性读入内存,当读取的数据非常大时,比如可以采用以下方法:只是在init里定义一个列表存储数据集每一个数据的文件名,标签如果太大也可以采用这种方法,然后可以等到getitem里面再根据读写第i个文件根据列表的文件名再把它读进来,保证内存的高效使用。
DataLoader用于拿出mini-batch,可以实例化。
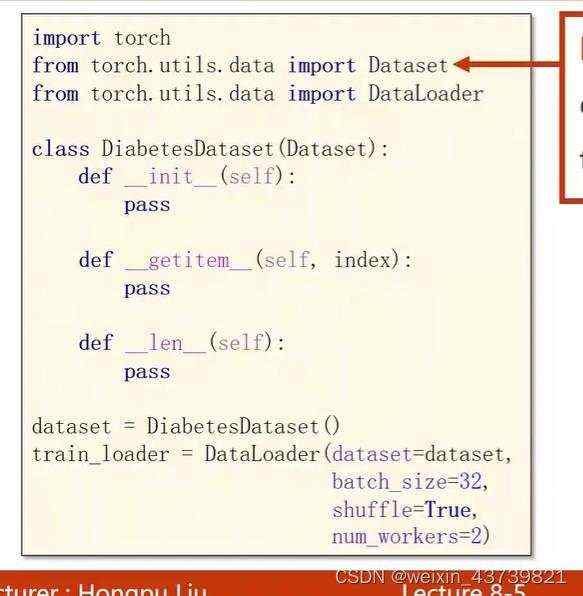
因为win和linux库函数的不同,直接调用含多线程(num_workers=2)的DataLoader实例化对象会报错,把它封装到一个if或者一个函数里就不会报错了。

定义Dataset读取全部数据的版本,xy.shape()返回数据集二维矩阵的行数和列数,这里我们取样本个数即行数。
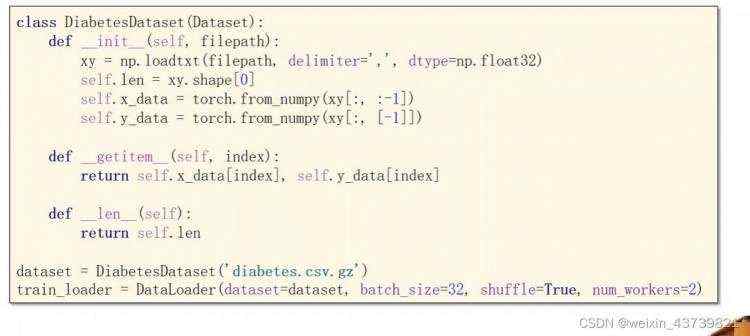
从train_loader获得xy的mini数据data,再将data赋值给inputs、lables分别对应x和y。这里一个inputs就是一个batch-size大小的x数据的张量。
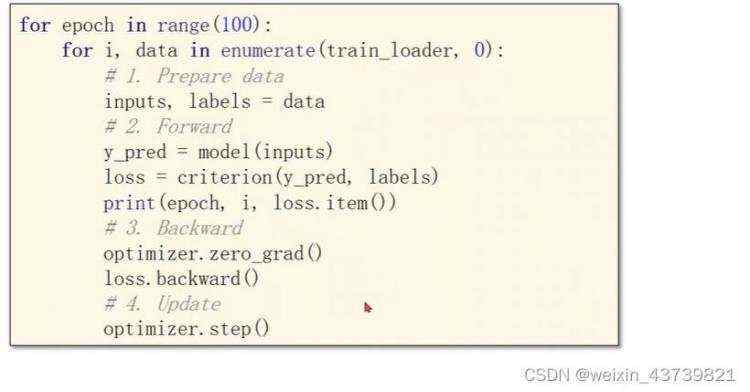
上面写的读入全部数据版本的完整代码如下:

datasets内置数据集
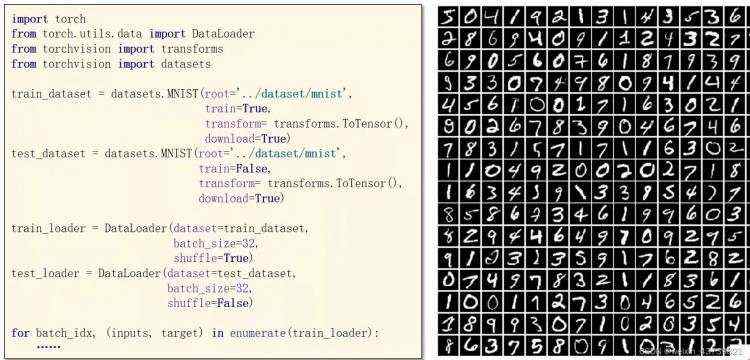
这里直接用MIST构造数据,不需要Dataset。
transform=transforms.ToTensor()表示数据要做怎样的变换,这里因为datasets里拿出来的数据是用Pillow读出来的,所以需要转换成张量,过程中会有一定的操作比如说图像像素值255缩放到0-1或-1到1。
这里测试的时候没有设置shuffle,因为测试的时候对模型没有改变,不需要打乱,且能保证每次输出测试样本的预测的顺序和输出样本数据序列保持一致便于观察。
最下面的循环省略了外层的epoch循环。
多分类问题
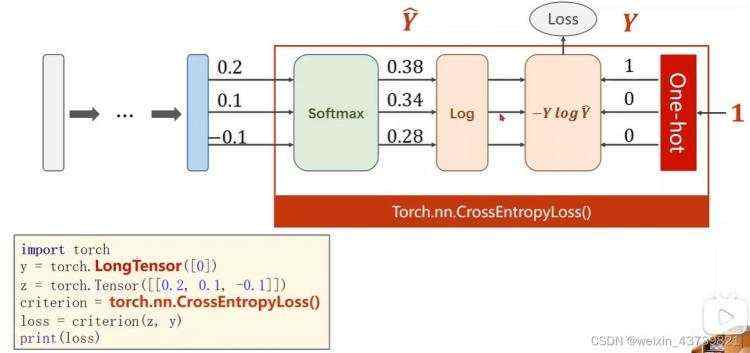
训练好的模型仅仅使用softmax来预测概率是可以的,但是优化的时候需要将softmax的结果取对数等计算来计算交叉熵,以此计算与真实标签的差距有多大,所以训练的时候需要计算交叉熵,交叉熵反应了预测值与真实标签之间的差异程度,且具有一些较好的性质。使用交叉熵时注意最后一层就不要使用激活函数了,直接传入进行计算。
pytorch提供求多分类的交叉熵损失函数(前面的BCE是二分类),把从softmax然后求对数等操作(NLLLoss)集成到一个接口,即CrossEntropyLoss。
在计算交叉熵时传入的y需要是LongTensor,即长整形张量。
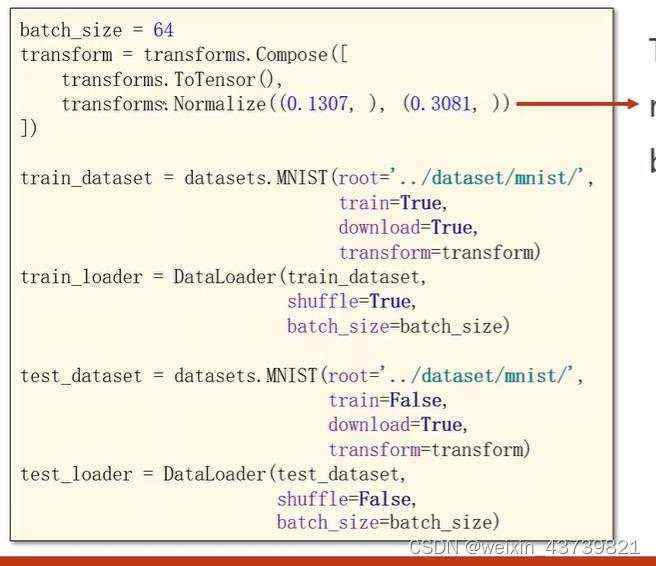
这里使用MNIST中28×28的数字图像分类作为例子。有一些常用的库。

读入的图像要转成Tensor把28×28×1转为1×28×28,然后根据MNIST的均值和标准差把像素值归一化,因为0-1的数据对神经网络来说训练效果更好。
网络层中的x=x.view(-1,784),-1代表自动识别样本个数,784表示将28×28的图像拼接成一个784的向量,得到的x为N×784的矩阵张量。
这里注意最后一层直接返回l5(x)不做激活,因为要传入交叉熵做softmax。

因为网络模型有点大了,用更好的优化算法,这里SGD+动量版本。

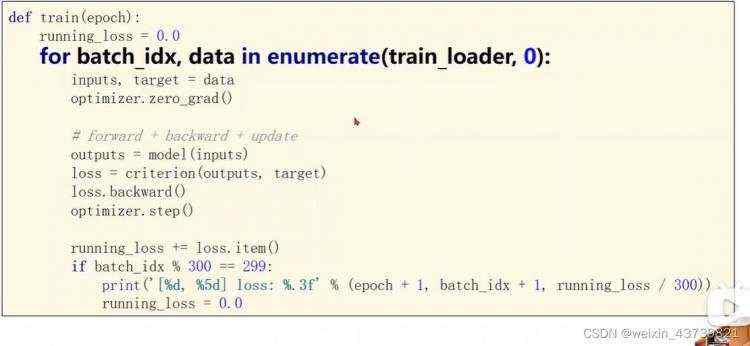
为了更好分离训练和测试,这里演示把一轮训练封装成函数的写法。
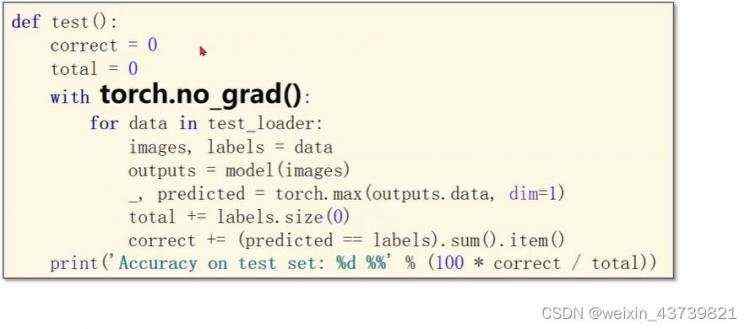
下面是一次测试的函数。测试不需要反向传播,写了torch.no_grad下面的代码就不会计算梯度了。
拿完数据传入模型做预测,预测完后拿到的结果矩阵每一行有十个量代表每个的预测值,我们需要拿到每一行的最大值下标是多少对应其分类,这里用到torch.max函数,这里可以指定沿着维度1即每行找最大值的下标(维度0是沿着每列),但是它返回俩个值,第一个是每行的最大值是多少,我们不需要所以传给变量_,下标传给predicted。
最后计算正确预测样本数和样本数计算正确率。
有了以上将来训练十轮就可以写成下面形式。也可以if epoch%10==9,十轮测试一次

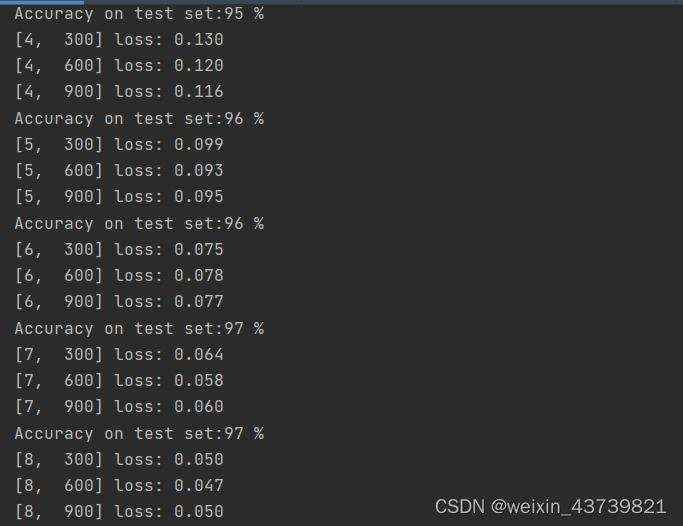
卷积神经网络
batch表示样本个数。第一个卷积层第一个参数1表示输入通道数,这里输入图片是灰度图所以为1,第二个参数表示输出通道,这里为10,表示这层有10个1×28×28的卷积核。kernel_size为5表示卷积核长宽为5,当然这个参数也可以传入元组用长宽不同的卷积核但一般不这么做。
第三层为池化层,传入2表示2×2的卷积核来池化,不指定stride默认stride为卷积核大小。这里没有涉及权重,不用定义多个,复用一个即可。
观察forward,可以先用数据求得n,即batch_size;这里先做第一次卷积然后池化然后RELU,然后再第二次卷积然后池化然后RELU与左边图片顺序有点不同问题不大。
最后要做一次view将20×4×4展开成320,再做全连接降为10维就和类别对应上,就可以扔进交叉熵获得损失做训练了。
将这些代码改到上个多分类版本中的代码中,其他的不用改,卷积网络就搭建好了。

TIPS:如何使用GPU来训练

在实例化model后加上这些语句,如果有多个显卡,还可以指定用哪个显卡:cuda:i,不同任务用不同显卡。然后不仅模型要迁移到GPU,计算的张量也要迁移进去,注意模型和数据要放到同一块显卡:

测试时也加入,就行了:

高级卷积之GoogleNet
目前常用的基础模块,经常在其基础上修改完成任务。画红线的部分都是一样的模块,称为一个Inception。
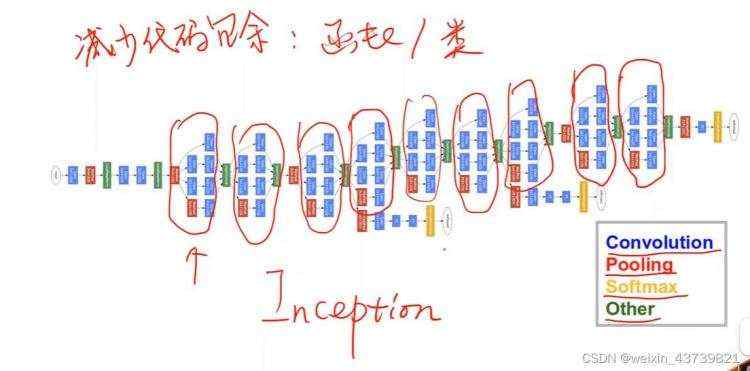
一个Inception如下所示,灵感来源于不知道卷积网络中使用什么样大小的卷积核合适,那么在一个Inception中使用多个大小的卷积核,那么效果好的卷积核在训练中权重也会越来越大,也就是给模型多了几条备选路径。
上下的Concatenate是各个张量拼接到一块,分成四个路径所以最后再拼接的时候要保证长宽一致,那么在不同卷积核卷积过程中要使用指定的padding、卷积核数量和池化类型。
为什么有那么多1×1的卷积?因为需要拿它们来改变输入张量通道数,而1×1的卷积能保证计算量大大减少
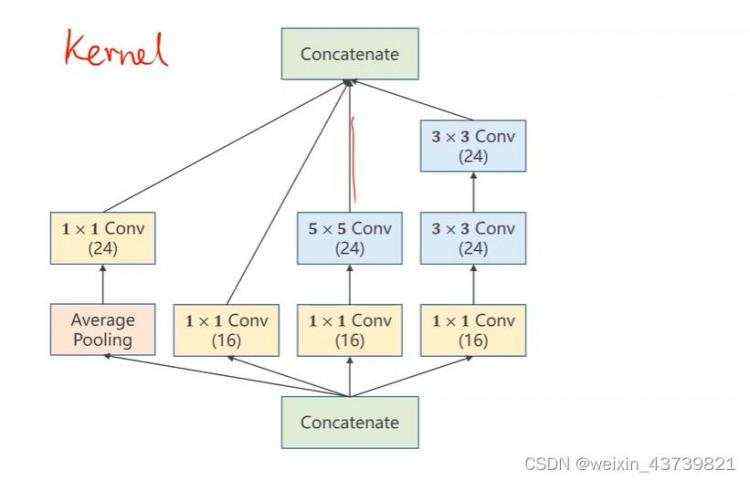
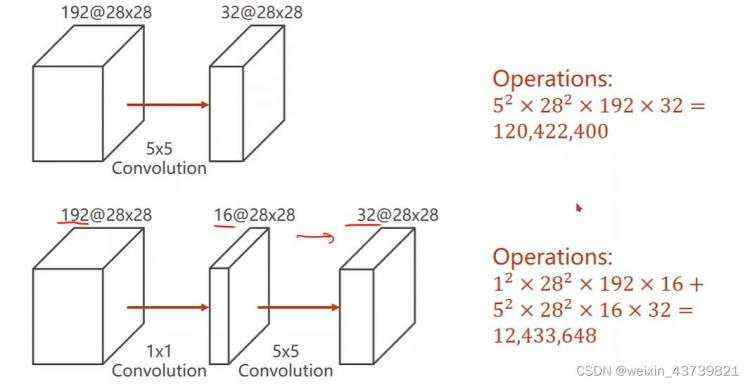
代码:
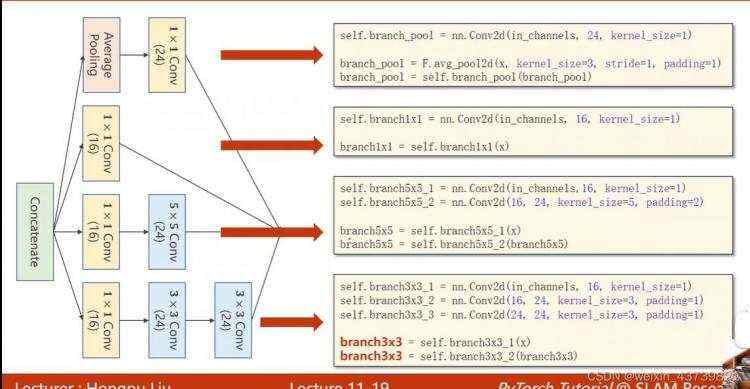
把张量拼接到一起,其中维度指定为1是因为张量的维度顺序是(batch,channel,width,height),我们要沿着通道拼接起来。

最后整合以上代码如下:

这里的1408、88等就是根据经过一些神经网络之后输出的有多少个元素多少个channel,这些值我们有时候也不需要自己去算,为了防止自己算的数目不对导致代码出错,定义这些模块的时候可以把最后俩行等先去掉,先根据它的输入构造一个像MNIST这样随机大小的张量输入,然后让模型算一次,然后看看输出的size是多少,这些值就可以求出来了,直接让机器去求就完了。
最后我们实际上在写代码的时候,发现某一次测试集准确率达到新高点,我们可以对当前网络的参数做一个备份存盘,也可以为了防止代码跑崩丢失模型使用存参数或者存模型的方法。
高级卷积之残差网络
对x求梯度,最低也是在梯度1的基础上加f对x的梯度,解决了梯度消失问题。
这里是Fx+x之后再做激活。
为了能让Fx和x相加,要保证中间俩层卷积层的输入和输出长宽和通道相同,即x和Fx的通道数、长宽完全一样。

构造好ResidualBlock,就可以写网络了:
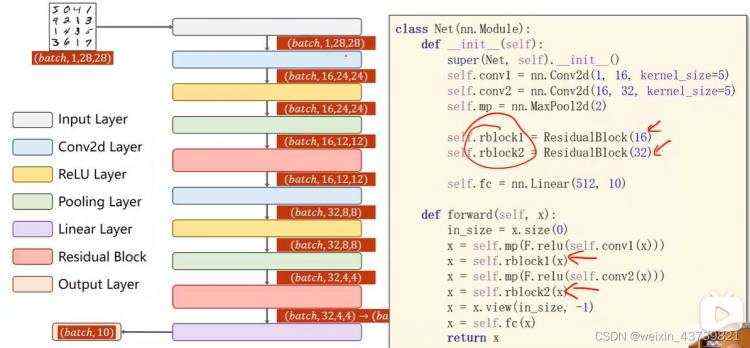
针对以上,如果以后有各种稀奇古怪的网络结构,可以嵌套的用类封装它们。
TIPS:刘二大人的学习建议

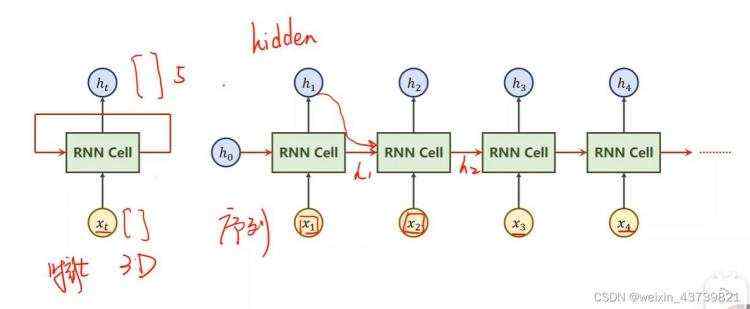
循环神经网络
适合前后有联系的连续数据预测,比如天气预测、股市预测、自然语言等,而这些用DNN、CNN来做计算量就太大或者没法做,h0是先验,也可以前面接上CNN+FC后面连上RNN,就可以完成图像到文本的转换,没有先验时h0也可以设为和h1同维度的全0。
注意RNN Cell是共享的,所有的RNN Cell都是同一个Linear(线性层),循环使用。







 京公网安备 11010802041100号
京公网安备 11010802041100号